本论文是一篇图像方面论文怎么写,关于图像检索的方法相关在职毕业论文范文。免费优秀的关于图像及信息检索及计算机方面论文范文资料,适合图像论文写作的大学硕士及本科毕业论文开题报告范文和学术职称论文参考文献下载。
[摘 要]本论文针对Intemet日益增长的多媒体信息检索应用需求,介绍了目前国内外现有的图像检索的系统及方法.
[关 键 词]多媒体信息检索;图像检索;TBIR;CBIR
[中图分类号]TP393 [文献标识码]A
[文章编号]1007-4309(2011)01-0074-1.5
随着通信和计算机的发展,存储技术的提高和Interact的日渐普及,我们拥有了海量的信息资源.这其中,不仅仅有简单的文本数据,更加包括了大量的图像、视频等多媒体信息.很明显,只有合理地组织这些资源,并研究高效的查询方法和检索方法,才有可能充分利用它们.于是各种针对Interact的图像搜索引擎应运而生,极大地方便了用户对Interact图像进行检索.
Web图像检索系统按照其组织和管理图像方式的不同,主要可以分为以下几类.基于文本的图像检索(Text-BasedImageRetrieval,简称TBIR)和基于内容的图像检索(content-BasedImageRetrieval,简称CBIR)以及综合文本信息和图像视觉信息的web图像检索.
一、基于文本的图像检索
传统的信息检索是基于关键字的信息检索,即输入关键字,检索出与之相匹配的文本对象.哪怕检索对象本身不是文本,而是例如声音、图形、图像、视频等其他类媒体,也是用关键字对这类媒体对象进行标识或索引,建立起与这类媒体对象之间的逻辑联系.
| 有关论文范文主题研究: | 图像相关论文范文 | 大学生适用: | 专升本论文、硕士论文 |
|---|---|---|---|
| 相关参考文献下载数量: | 31 | 写作解决问题: | 写作技巧 |
| 毕业论文开题报告: | 文献综述、论文摘要 | 职称论文适用: | 期刊目录、职称评中级 |
| 所属大学生专业类别: | 写作技巧 | 论文题目推荐度: | 经典题目 |
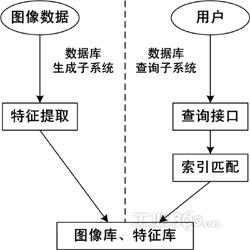
TBIR的历史可以追溯到20世纪70年代,由于数据库技术的进步而建立和发展了基于文本的图像检索技术,并取得了一定成果,例如数据建模、多维数据索引、查询优化和查询评估等.图像数据研究者们在对图像进行文本标注的基础上,对图像进行基于关键字的检索.其基本步骤是先对图像文件建立相应的关键字或描述字段,并将图像的存储路径与该关键
图像方面论文范文
本文来自:http://www.sxsky.net/zhengzhi/050872472.html
早期的图像检索系统采用文本数据形式对图像进行人工注释,建立图像索引数据库.这种人工标注的方法适合有限范围的图像库管理系统,如人事档案照片库、动物图谱库、商标图案库等.但在Web环境中,Web图像数据是海量的,无法采用人工方式对图像进行广泛的关键信息标注,只得借助Web中相关的文本信息,采用适当的算法提取图像的主题,实现图像自动标注.显然,对图像自动标注的准确性依赖于Web中图像关键信息的提取算法.目前这些关键信息的提取主要从以下几个图像的外部信息中提取:图像的文件名及网址、图像的替代文字、图像周围的文字、图像所在页面的标题、图像的超链接、图像所在网页彼此间的链接.
目前多数图像搜索引擎(网站),如Google、Yahoo、Al-taVista、Infoseek、LyCOS、Scour、WebSeek、搜狐等,普遍采用此种方式.有的研究者把网页按照其组织内容的框架和结构将网页分割成多个基本块,然后将块内的元素作为一个基本的语义单元实现Web检索.有些研究者使用网页内的链接信息实现Web检索.还有些人使用缩略图帮助web用户在基于文本检索的结果中更好地定位感兴趣的图像;部分研究者使用网页的文本片段(TextSnippet)和图像片段(ImageSnippet)帮助用户快速定位其感兴趣的网页.
互联网上的网页搜索是由网络爬虫完成的,但是随着Web的发展,其结构越来越复杂,其中的网页数量越来越多,通用爬虫越发不可能访问WebL的所有网页并及时进行更新,简短的关 键 词输入无法表达出用户的复杂查询语义.

怎样写图像毕业论文
播放:20865次 评论:7622人
“主题爬虫”这一概念是由S,Chakrabarti在1999年WorldWideWeb大会上首次提出的.与一般的网络爬虫不同,主题网络爬虫不是对所有链接不加选择地爬行,而是面向主题地、有选择地爬行.主题爬虫分析每个网页的链接,预测哪些链接指向的网页可能和预定主题相关,对这些链接进行优先爬行,而舍弃那些和主题无关的链接.
目前,主题网络爬虫技术研究正在成为一个热点.在1999年出现了IBMFocusedCrawler.如今,主题爬虫又有了新的发展,国外典型的系统有ContextGraphsFocusedCrawler、WTMS系统等.
二、基于内容的图像检索
20世纪90年代初,人工智能、数字信号处理、统计学、自然语言理解、数据库技术、心理学、计算机视觉、模式识别和信息处理等技术都得到了不同程度的发展.在此基础上,为了克服基于文本信息检索带来的困难,提出基于内容的图像检索(content-BasedImageRetrieval,简称CBIR)技术,从可视化角度对图像检索进行探讨.所谓基于内容的图像检索,是使用图像的颜色、纹理、形状等低层视觉特征从图像库中查找含有特定对象的图像.它区别于传统的检索手段,融合了图像理解技术,从而可以提供更有效的检索手段并实现自动化检索.CBIR具有如下特点:直接从图像中提取特征建立索引;检索匹配是一种近似匹配,这一点与常规数据库检索的精确匹配方法有明显不同;特征提取和索引建立可由计算机自动实现,避免了人工描述的主观性,大大减少了工作量.图像的视觉特征是在像素数据基础上提取的,可用于基于图像直观形象的检索.
在这期间,比较典型的基于内容的图像检索系统代表有QBIC、Photobook、Virage、Visualseek和MARs等.这些系统都遵循同一个模式:用图像的颜色、形状、纹理等视觉特征表示图像的内容,利用查询例图的视觉特征和底层数据库中图像的视觉特征进行匹配来完成检索.
从目前基于内容的图像搜索演示系统的检索结果看,检索效果并不理想,其根本原因是低层的视觉特征与高层的图像语义之间存在的“语义鸿沟”.低层的视觉特征不能代表图像丰富的内涵,用户搜索图像更关心的是概念层次上图像的内容和图像表现的寓意,也就是图像的高层语义.因此,图像检索的理想方式是根据图像的语义进行检索,目前将低层图像特征映射到高层语义的图像语义生成方法主要分为三种,分别是基于知识的语义提取、人工交互语义提取和利用外部信息源的语义生成.
三、综合文本信息和图像视觉信息的web图像检索
Web图像的文本信息和视觉信息在Web图像检索中都具有十分重要的作用,因此许多研究者开始研究基于包含这两种信息在内的Web图像检索.由于各种信息之间是异构的,很难直接将它们融合在一起,所以针对不同信息通常采用不同的模型实现Web图像检索.例如文本信息主要采用传统的TBIR模型,图像视觉信息主要采用传统的CBIR模型,而链接信息则主要采用基于图论的模型.由于不同信息之间的异构性,很难评价不同的信息对于Web图像检索的贡献,因此多个模型之间的最优组合是一个不可解问题.
一部分研究者使用文本信息和图像低层视觉信息检索图像,在计算文本信息之间的相似性时通过计算它们对应向量之间夹角的余弦,而计算视觉信息之间的相似性时通过计算它们对应向量之间的欧几里德距离.然后使用线性
图像方面论文范文,与图像检索的方法相关论文怎么写参考文献资料:
 13888888888
13888888888
 点击咨询
点击咨询 